
DeepSeek has launched a groundbreaking open-source AI model called DeepSeekMath-V2 that tackles some of the toughest math problems in the world, hitting gold-medal levels at major competitions like the International Mathematical Olympiad. This Hangzhou-based Chinese startup made the model freely available on platforms such as Hugging Face and GitHub, letting developers tweak and use it without restrictions under the Apache 2.0 license. The news, which broke late November 2025, has sparked excitement across the tech world, with experts calling it a game-changer for open AI in math reasoning.
Key Points
- DeepSeekMath-V2 achieves gold level at IMO 2025, top scores at CMO 2024, and near-perfect on Putnam 2024 (118/120 vs best human 90).
- Features a dual architecture with generator and verifier working to self-correct proofs, shifting AI math from final-answer focus to process validation.
- Outperforms or matches top proprietary AI models like Google’s Gemini DeepThink, especially strong in geometry problem solving.
- Released fully open-source under Apache 2.0, lowering barriers for global AI research and innovation.
- Marks a strategic advancement for Chinese AI in leading open models against Western proprietary AI dominance.
The new model distinguishes itself with a unique generator-verifier architecture that self-verifies its proofs step-by-step, significantly reducing logical errors common in previous AI approaches that focused solely on final answer accuracy. This self-correcting mechanism enables DeepSeekMath-V2 to deliver rigorously validated mathematical reasoning, marking a fundamental shift from “result-oriented” to “process-oriented” AI evaluation, which enhances trust and applicability in scientific research and engineering workflows.
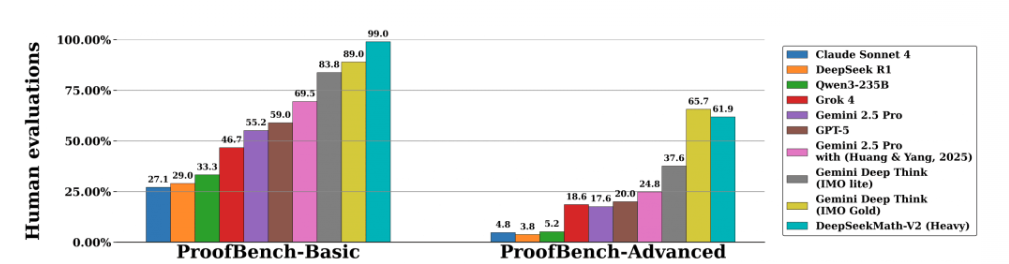
When compared to leading AI math models like Google DeepMind’s Gemini DeepThink, DeepSeekMath-V2 demonstrates competitive or superior performance. On benchmarks such as the IMO-ProofBench, it achieved an 85% pass rate for short proofs and maintained a high accuracy rate on more complex tasks. While Gemini DeepThink scored approximately 65.7% on advanced proofs, DeepSeekMath-V2 closely matched this with around 61.9%, and significantly outperformed others on the basic proof set.
The global impact of DeepSeekMath-V2 is significant in democratizing elite AI technology. By offering a state-of-the-art, open-source math AI model, DeepSeek facilitates wider access to powerful reasoning systems beyond proprietary platforms dominated by U.S.-based tech giants. This move aligns with broader trends in AI openness, empowering researchers worldwide, fostering innovation, and potentially accelerating advancements in fields like cryptography, drug discovery, and chip design – a marked push towards more transparent, verifiable AI.
DeepSeekMath-V2’s competition results highlight its extraordinary capabilities. It surpassed the gold medal threshold at the International Mathematical Olympiad 2025, a contest recognized as one of the toughest global math challenges. It also excelled in the China Mathematical Olympiad 2024 and achieved an unprecedented 118 out of 120 on the Putnam competition 2024, where the top human score was 90, underscoring the model’s advanced problem-solving prowess.
(source: officechai.com)
Open-Source Impact
Releasing weights openly lowers barriers for global devs, unlike closed models from OpenAI or Google DeepMind that hit similar IMO golds but stay locked. Hugging Face CEO Clement Delangue posted on X: “Imagine owning the brain of one of the best mathematicians in the world for free.” Now anyone can run it locally or build on top.
Experts see this democratizing high-level math AI. Tong Xie, a chemist at UNSW Sydney, praised the natural language checks as cost-effective and scalable over resource-hungry alternatives. It fuels research in fields needing proofs, like physics or computer science, without big budgets.
Comparisons to Rivals
| Model | IMO 2025 | Putnam 2024 | Open Source | Verification Method |
|---|---|---|---|---|
| DeepSeekMath V2 | Gold (83.3%, 5/6) | 118/120 | Yes | Self verification using natural language |
| OpenAI o1 | Gold equivalent | High 90s | No | Proprietary verification |
| Google AlphaProof / DeepThink | Silver or Gold | Not available | No | External lean based verification |
| Top Human | Varies, around gold level | 90/120 | Not applicable | Manual verification |
Final Thought
DeepSeekMath-V2 sets a new benchmark for AI in mathematics by proving self-verifiable reasoning can deliver gold-standard results on elite competitions, opening doors to reliable tools for research, education, and formal verification worldwide. This open release challenges proprietary dominance and promises faster progress toward trustworthy AI that matches human rigor in complex proofs and discoveries.
Explore More
- Pickleball Statistics by Market Size and Growth
- Semiconductor Statistics, Facts and Performance
- AI Agents Statistics: Market Size, Adoption Rate and Trends
- Voice AI Agents Statistics, Market Size and Adoption Trends
- Streaming Services Statistics by Category and Emerging Trends
- Top Drone Companies Shaping Global Market Growth